
피지여행 구현 이야기
PG Travel implementation story
피지여행 프로젝트에서는 다음 7개 논문을 살펴보았습니다. 각 논문에 대한 리뷰는 이전 글들에서 다루고 있습니다.
- [1] R. Sutton, et al., "Policy Gradient Methods for Reinforcement Learning with Function Approximation", NIPS 2000.
- [2] D. Silver, et al., "Deterministic Policy Gradient Algorithms", ICML 2014.
- [3] T. Lillicrap, et al., "Continuous Control with Deep Reinforcement Learning", ICLR 2016.
- [4] S. Kakade, "A Natural Policy Gradient", NIPS 2002.
- [5] J. Schulman, et al., "Trust Region Policy Optimization", ICML 2015.
- [6] J. Schulman, et al., "High-Dimensional Continuous Control using Generalized Advantage Estimation", ICLR 2016.
- [7] J. Schulman, et al., "Proximal Policy Optimization Algorithms", arXiv, https://arxiv.org/pdf/1707.06347.pdf.
강화학습 알고리즘을 이해하는데 있어서 논문을 보고 이론적인 부분을 알아가는 것이 좋습니다. 하지만 실제 코드로 돌아가는 것은 논문만 보고는 알 수 없는 경우가 많습니다. 따라서 피지여행 프로젝트에서는 위 7개 논문 중에 DPG와 DDPG를 제외한 알고리즘을 구현해보았습니다. 구현한 알고리즘은 다음 4개입니다. 이 때, TRPO와 PPO 구현에는 GAE(General Advantage Estimator)가 함께 들어갑니다.
- Vanilla Policy Gradient [1]
- TNPG(Truncated Natural Policy Gradient) [4]
- TRPO(Trust Region Policy Optimization) [5]
- PPO(Proximal Policy Optimization) [7].
바닥부터 저희가 구현한 것은 아니며 다음 코드들을 참고해서 구현하였습니다. Vanilla PG의 경우 RLCode의 깃헙을 참고하였습니다.
GAE와 TRPO, PPO 논문에서는 Mujoco라는 물리 시뮬레이션을 학습 환경으로 사용합니다. 따라서 저희도 Mujoco로 처음 시작을 하였습니다. 하지만 Mujoco는 1달만 무료이고 그 이후부터 유료이며 확장성이 떨어집니다. Unity ml-agent는 기존 Unity를 그대로 사용하면서 쉽게 강화학습 에이전트를 붙일 수 있도록 설계되어 있습니다. Unity ml-agent에서는 저희가 살펴본 알고리즘 중에 가장 최신 알고리즘은 PPO를 적용해봤습니다. 기본적으로 제공하는 환경 이외에 저희가 customize 한 환경에서도 학습해봤습니다.
- mujoco-py: https://github.com/openai/mujoco-py
- Unity ml-agent: https://github.com/Unity-Technologies/ml-agents
코드를 구현하고 환경에서 학습을 시키면서 여러가지 이슈들이 있었고 해결해내가는 과정이 있었습니다. 그 과정을 간단히 정리해서 공유하면 PG를 공부하는 분들께 도움일 될 것 같습니다. 저희가 구현한 순서대로 1. Mujoco 학습 2. Unity ml-agent 학습 3. Unity Curved Surface 로 이 포스트가 진행됩니다.
1. Mujoco 학습
일명 "Continuous control" 문제는 action이 discrete하지 않고 continuous한 경우를 말합니다. Mujoco는 continuous control에 강화학습을 적용한 논문들이 애용하는 시뮬레이터입니다. 저희가 리뷰한 논문 중에서도 TRPO, PPO, GAE에서 Mujoco를 사용합니다. 따라서 저희가 처음 피지여행 알고리즘을 적용한 환경으로 Mujoco를 선택했습니다.
Mujoco에는 Ant, HalfCheetah, Hopper, Humanoid, HumanoidStandup, InvertedPendulum, Reacher, Swimmer, Walker2d 과 같은 환경이 있습니다. 그 중에서 Hopper에 맞춰서 학습이 되도록 코드를 구현하였습니다. Mujoco 설치와 관련된 내용은 Wiki에 있습니다.
1.1 Hopper
Hopper는 외다리로 뛰어가는 것을 학습하는 것이 목표입니다. Hopper는 다음과 같이 생겼습니다.

환경을 이해하려면 환경의 상태와 행동, 보상 그리고 학습하고 싶은 목표를 알아야합니다.
- 상태 : 관절의 위치, 각도, 각속도
- 행동 : 관절의 가해지는 토크
- 보상 : 앞으로 나아가는 속도
- 목표 : 최대한 앞으로 많이 나아가기
즉 에이전트는 time step마다 관절의 위치와 각도를 받아와서 그 상태에서 어떻게 움직여야 앞으로 나아갈 수 있는지를 학습해야 합니다. 행동은 discrete action이 아닌 continuous action으로 -1과 1사이의 값을 가집니다. 만약 행동이 -1이라면 해당 관절에 시계반대방향으로 토크를 주는 것이고 행동이 +1이라면 해당 관절에 시계방향으로 토크를 주는 것입니다.
continuous action을 주는 방법은 네트워크(Actor)의 output layer에서 activation function으로 tanh와 같은 것을 사용해서 continuous한 값을 출력하는 것이 있습니다. 하지만 피지여행 코드 구현에서는 action을 gaussian distribution에서 sampling 하였습니다. 이렇게 하면 분산을 일정하게 유지하면서 지속적인 exploration을 할 수 있습니다. 간단하게 그림으로 보자면 다음과 같습니다.
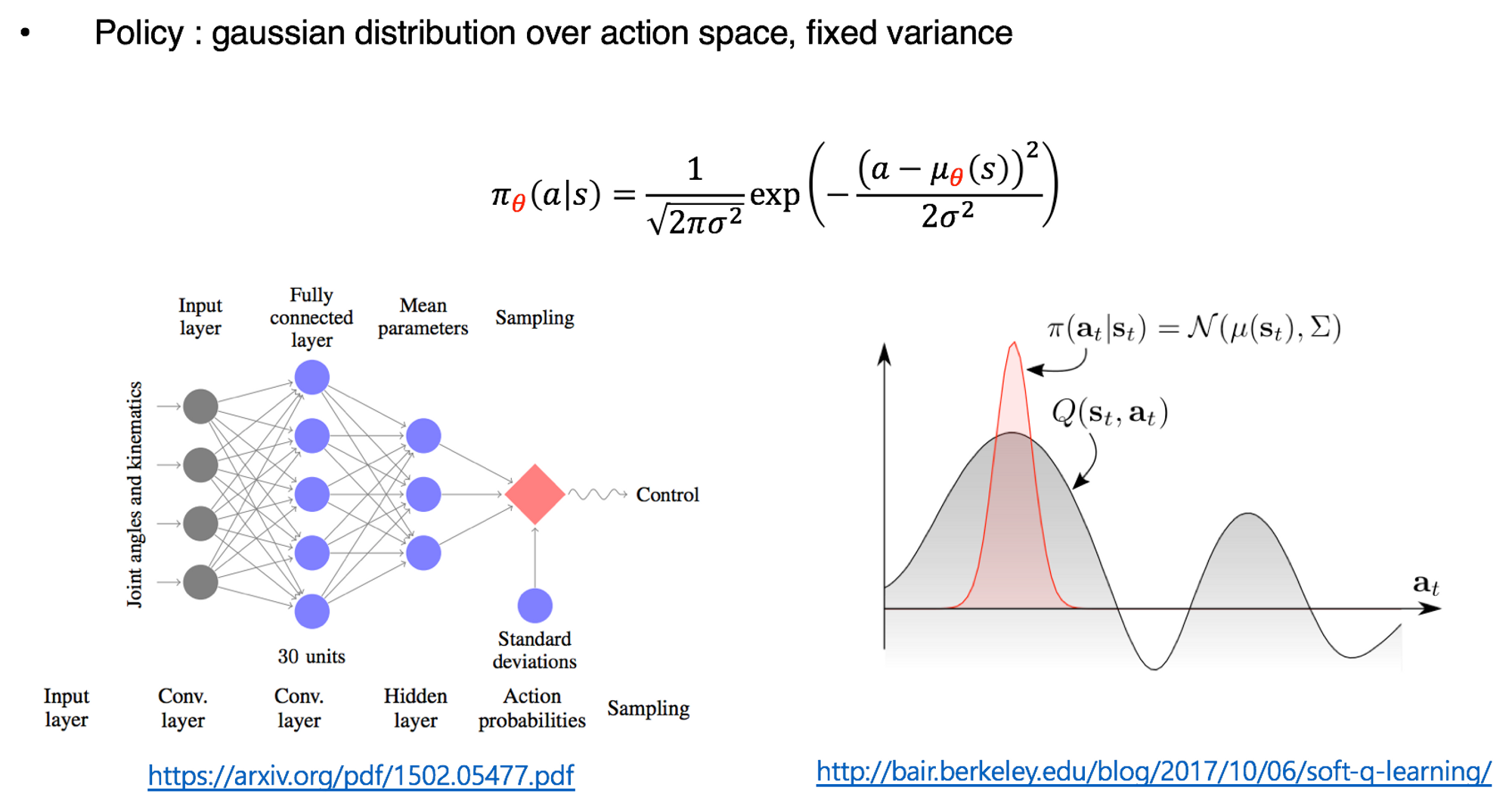
네트워크 구조와 행동을 선택하는 부분은 다음과 같습니다. Hidden Layer의 activation function으로 tanh를 사용했으며(ReLU를 테스트해보지는 않았습니다. 기존 TRPO, PPO 구현들과 논문에서 tanh를 사용하기 때문에 저희도 사용했습니다. 뒤에 유니티 환경에서는 Swish라는 것을 사용합니다.) log std를 0으로 고정함으로서 일정한 폭을 가지는 분포를 만들어낼 수 있습니다. 이 분포로부터 action을 sampling 합니다.

1.2 Vanilla PG
Vanilla PG는 Actor-Critic의 가장 간단한 형태입니다. Vanilla PG는 이후의 구현에 대한 baseline이 됩니다. 구현이 가장 간단하면서 학습이 안되는 것은 아닙니다. 따라서 코드 전체 구조를 잡는데 Vanilla PG를 짜는 것이 도움이 됩니다. 전반적인 코드 구조는 다음과 같습니다.
- iteration 마다 일정한 step 수만큼 환경에서 진행해서 샘플을 모은다
- 모은 샘플로 Actor와 Critic을 학습한다
- 반복한다
episodes = 0
for iter in range(15000):
actor.eval(), critic.eval()
memory = deque()
while steps < 2048:
episodes += 1
state = env.reset()
state = running_state(state)
score = 0
for _ in range(10000):
mu, std, _ = actor(torch.Tensor(state).unsqueeze(0))
action = get_action(mu, std)[0]
next_state, reward, done, _ = env.step(action)
next_state = running_state(next_state)
if done:
mask = 0
else:
mask = 1
memory.append([state, action, reward, mask])
state = next_state
if done:
break
actor.train(), critic.train()
train_model(actor, critic, memory, actor_optim, critic_optim)memory에 sample을 저장할 때 sample은 state와 action, reward, mask(마지막 state일 경우 0 나머지 1)입니다. mask의 경우 뒤에서 return이나 advantage를 계산할 때 사용됩니다. 또 하나 염두에 두어야할 것은 running_state 입니다. running_state는 input으로 들어오는 state의 scale이 일정하지 않기 때문에 사용합니다. 즉 state의 각 dimension을 평균 0 분산 1로 standardization 하는 것입니다. 따라서 모델을 저장할 때 각 dimension 마다의 평균과 분산도 같이 저장해서 테스트할 때 불러와서 사용해야 합니다.
Vanilla PG의 경우 학습 부분이 상당히 간단합니다. 다음 코드를 보시면 메모리에서 state, action, reward, mask를 꺼냅니다. reward와 mask를 통해 return을 구할 수 있고 이 return을 통해 actor를 업데이트 할 수 있습니다 (REINFORCE 알고리즘을 떠올리시면 됩니다). 여기서 critic이 하는 일은 없지만 뒤의 알고리즘들과 코드의 통일성을 위해 fake로 넣어놨습니다. Return은 평균을 빼고 분산으로 나눠서 standardize 합니다.
def train_model(actor, critic, memory, actor_optim, critic_optim):
memory = np.array(memory)
states = np.vstack(memory[:, 0])
actions = list(memory[:, 1])
rewards = list(memory[:, 2])
masks = list(memory[:, 3])
returns = get_returns(rewards, masks)
train_critic(critic, states, returns, critic_optim)
train_actor(actor, returns, states, actions, actor_optim)
return returns이 코드로 Hopper 환경에서 학습한 그래프는 다음과 같습니다.

1.3 TNPG
NPG를 이용한 parameter update 식은 다음과 같습니다.
$$ \bar{w}=F(\theta)^{-1}\nabla\eta(\theta) $$
NPG를 구현하려면 KL-divergence의 Hessian의 inverse를 구해야하는 문제가 생깁니다. 현재와 같이 Deep Neural Network를 쓰는 경우에 Hessian의 inverse를 직접적으로 구하는 것은 computationally inefficient 합니다. 따라서 직접 구하지 않고 Conjugate gradient 방법을 사용해서 Fisher Vector Product ($F^{-1}g$)를 구합니다. 이러한 알고리즘을 Truncated Natural Policy Gradient(TNPG)라고 부릅니다.
TNPG에서 parameter update를 구하는 과정은 다음과 같습니다.
- Return 구하기
- Critic 학습하기
- logp * return → loss 구하기
- loss의 미분과 kl-divergence의 2차 미분을 통해 step direction 구하기
- 구한 step direction으로 parameter update
def train_model(actor, critic, memory, actor_optim, critic_optim):
memory = np.array(memory)
states = np.vstack(memory[:, 0])
actions = list(memory[:, 1])
rewards = list(memory[:, 2])
masks = list(memory[:, 3])
# ----------------------------
# step 1: get returns
returns = get_returns(rewards, masks)
# ----------------------------
# step 2: train critic several steps with respect to returns
train_critic(critic, states, returns, critic_optim)
# ----------------------------
# step 3: get gradient of loss and hessian of kl
loss = get_loss(actor, returns, states, actions)
loss_grad = torch.autograd.grad(loss, actor.parameters())
loss_grad = flat_grad(loss_grad)
step_dir = conjugate_gradient(actor, states, loss_grad.data, nsteps=10)
# ----------------------------
# step 4: get step direction and step size and update actor
params = flat_params(actor)
new_params = params + 0.5 * step_dir
update_model(actor, new_params)conjugate gradient 코드는 OpenAI baseline에서 가져왔습니다. 이 코드는 원래 John schulmann 개인 repository에 있는 그대로 사용하는 것입니다. nsteps 만큼 iterataion을 반복하며 결국 x를 구하는 것인데 이 x가 step direction 입니다.
# from openai baseline code
# <https://github.com/openai/baselines/blob/master/baselines/common/cg.py>
def conjugate_gradient(actor, states, b, nsteps, residual_tol=1e-10):
x = torch.zeros(b.size())
r = b.clone()
p = b.clone()
rdotr = torch.dot(r, r)
for i in range(nsteps):
_Avp = fisher_vector_product(actor, states, p)
alpha = rdotr / torch.dot(p, _Avp)
x += alpha * p
r -= alpha * _Avp
new_rdotr = torch.dot(r, r)
betta = new_rdotr / rdotr
p = r + betta * p
rdotr = new_rdotr
if rdotr < residual_tol:
break
return xfisher_vector_product는 kl-divergence의 2차미분과 어떠한 vector의 곱인데 p는 처음에 gradient 값이었다가 점차 업데이트가 됩니다. kl-divergence의 2차 미분을 구하는 과정은 다음과 같습니다. 일단 kl-divergence를 현재 policy에 대해서 구한 다음에 actor parameter에 대해서 미분합니다. 이렇게 미분한 gradient를 일단 flat하게 핀 다음에 p라는 벡터와 곱해서 하나의 값으로 만듭니다. 그 값을 다시 actor의 parameter로 만듦으로서 따로 KL-divergence의 2차미분을 구하지않고 Fisher vector product를 구할 수 있습니다.
def fisher_vector_product(actor, states, p):
p.detach()
kl = kl_divergence(new_actor=actor, old_actor=actor, states=states)
kl = kl.mean()
kl_grad = torch.autograd.grad(kl, actor.parameters(), create_graph=True)
kl_grad = flat_grad(kl_grad) # check kl_grad == 0
kl_grad_p = (kl_grad * p).sum()
kl_hessian_p = torch.autograd.grad(kl_grad_p, actor.parameters())
kl_hessian_p = flat_hessian(kl_hessian_p)
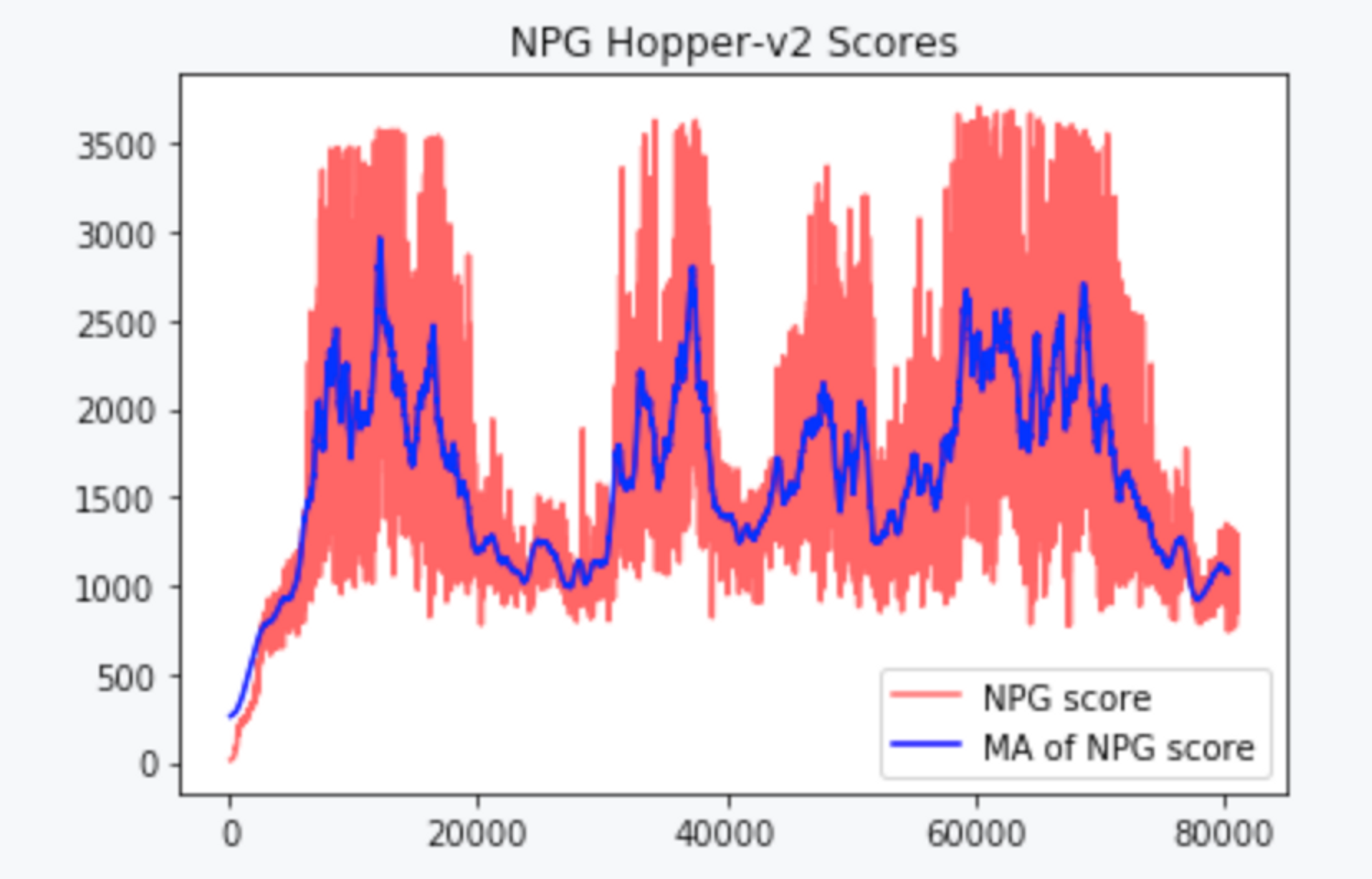
return kl_hessian_p + 0.1 * pTNPG 학습 결과는 다음과 같습니다.
1.4 TRPO
TRPO와 NPG가 다른 점은 surrogate loss 사용과 trust region 입니다. 하지만 실제로 구현해서 학습을 시켜본 결과 trust region을 넘어가서 back tracking line search를 하는 경우는 거의 없습니다. 따라서 주된 변화는 surrogate loss에 있다고 보셔도 됩니다. Surrogate loss에서 advantage function을 사용하는데 본 코드 구현에서는 GAE를 사용하였습니다. TRPO 업데이트 식은 다음과 같습니다. Q function 위치에 GAE가 들어갑니다.
$$ \max_\theta\quad E_{s\sim\rho_{\theta_\mathrm{old} },a\sim q}\left[\frac{\pi_\theta(a\vert s)}{q(a\vert s)}Q_{\theta_\mathrm{old} }(s,a)\right] \\\ \\ \mathrm{s.t.\ }E_{s\sim\rho_{\theta_\mathrm{old} }}\left[D_\mathrm{KL}\left(\pi_{\theta_\mathrm{old} }(\cdot\vert s) \parallel \pi_\theta(\cdot\vert s)\right)\right] \leq \delta $$
GAE를 구하는 코드는 다음과 같습니다. GAE는 td-error의 discounted summation이라고 볼 수 있습니다. 마지막에 advants를 standardization 하는 것은 return에서 하는 것과 같은 효과를 봅니다. 하지만 standardization을 안하고 실험을 해보지는 않았습니다.
def get_gae(rewards, masks, values):
rewards = torch.Tensor(rewards)
masks = torch.Tensor(masks)
returns = torch.zeros_like(rewards)
advants = torch.zeros_like(rewards)
running_returns = 0
previous_value = 0
running_advants = 0
for t in reversed(range(0, len(rewards))):
running_returns = rewards[t] + hp.gamma * running_returns * masks[t]
running_tderror = rewards[t] + hp.gamma * previous_value * masks[t] - \\\\
values.data[t]
running_advants = running_tderror + hp.gamma * hp.lamda * \\\\
running_advants * masks[t]
returns[t] = running_returns
previous_value = values.data[t]
advants[t] = running_advants
advants = (advants - advants.mean()) / advants.std()
return returns, advantsSurrogate loss를 구하는 코드는 다음과 같습니다. Advantage function(GAE)를 구하고 나면 이전 policy와 현재 policy 사이의 ratio를 구해서 advantage function에 곱하면 됩니다. 이 때 사실 old policy와 new policy는 값은 같지만 old policy는 clone()이나 detach()를 사용해서 update가 안되게 만들어줍니다.
def surrogate_loss(actor, advants, states, old_policy, actions):
mu, std, logstd = actor(torch.Tensor(states))
new_policy = log_density(torch.Tensor(actions), mu, std, logstd)
advants = advants.unsqueeze(1)
surrogate = advants * torch.exp(new_policy - old_policy)
surrogate = surrogate.mean()
return surrogateActor의 step direction을 구하는 것은 TNPG와 동일합니다. TNPG에서는 step direction으로 바로 업데이트 했지만 TRPO는 다음과 같은 작업을 해줍니다. Full step을 구하는 과정이라고 볼 수 있습니다.
# ----------------------------
# step 4: get step direction and step size and full step
params = flat_params(actor)
shs = 0.5 * (step_dir * fisher_vector_product(actor, states, step_dir)
).sum(0, keepdim=True)
step_size = 1 / torch.sqrt(shs / hp.max_kl)[0]
full_step = step_size * step_dir이렇게 full step을 구하고 나면 Trust region optimization 단계에 들어갑니다. expected improvement는 구한 step 만큼 parameter space에서 움직였을 때 예상되는 performance 변화입니다. 이 값은 kl-divergence와 함께 trust region 안에 있는지 밖에 있는지 판단하는 근거가 됩니다. expected improve는 출발점에서의 gradient * full step으로 구합니다. 그리고 10번을 돌아가며 Back-tracking line search를 실시합니다. 처음에는 full step 만큼 가본 다음에 kl-divergence와 emprovement를 통해 trust region 안이면 루프 탈출, 밖이면 full step을 반만큼 쪼개서 다시 이 과정을 반복합니다.
# ----------------------------
# step 5: do backtracking line search for n times
old_actor = Actor(actor.num_inputs, actor.num_outputs)
update_model(old_actor, params)
expected_improve = (loss_grad * full_step).sum(0, keepdim=True)
expected_improve = expected_improve.data.numpy()
flag = False
fraction = 1.0
for i in range(10):
new_params = params + fraction * full_step
update_model(actor, new_params)
new_loss = surrogate_loss(actor, advants, states, old_policy.detach(),
actions)
new_loss = new_loss.data.numpy()
loss_improve = new_loss - loss
expected_improve *= fraction
kl = kl_divergence(new_actor=actor, old_actor=old_actor, states=states)
kl = kl.mean()
print('kl: {:.4f} loss improve: {:.4f} expected improve: {:.4f} '
'number of line search: {}'
.format(kl.data.numpy(), loss_improve, expected_improve[0], i))
# see https: // en.wikipedia.org / wiki / Backtracking_line_search
if kl < hp.max_kl and (loss_improve / expected_improve) > 0.5:
flag = True
break
fraction *= 0.5Critic의 학습은 단순히 value function과 return의 MSE error를 계산해서 loss로 잡고 loss를 최소화하도록 학습합니다. TRPO 학습 결과는 다음과 같습니다.

1.5 PPO
PPO의 장점을 꼽으라면 GPU 사용하기 좋고 sample efficiency가 늘어난다는 것입니다. TNPG와 TRPO의 경우 한 번 모은 sample은 모델을 단 한 번 업데이트하는데 사용하지만 PPO의 경우 몇 mini-batch로 epoch를 돌리기 때문입니다. GAE를 사용한다는 것은 같고 Conjugate gradient나 Fisher vector product나 back tracking line search가 다 빠집니다. 대신 loss function clip으로 monotonic improvement를 보장하게 학습합니다. 따라서 코드가 상당히 간단해집니다.
다음 코드 부분이 PPO의 전체라고 봐도 무방합니다. PPO는 다음과 같은 순서로 학습합니다.
- batch를 random suffling하고 mini batch를 추출
- value function 구하기
- critic loss 구하기 (clip을 사용해도 되고 TRPO와 같이 그냥 학습시켜도 됌)
- surrogate loss 구하기
- surrogate loss clip해서 actor loss 만들기
- actor와 critic 업데이트
Actor의 loss를 구하는 것은 다음 식의 값을 구하는 것입니다. 이 식을 구하려면 ratio에 한 번 클립하고 loss 값을 한 번 min을 취하면 됩니다.
$$ L^{CLIP}(\theta) = \hat{E}_t [min(r_t(\theta) \, \hat{A}_t, clip(r_t(\theta), 1-\epsilon, 1+\epsilon) \, \hat{A}_t)] $$
이 코드 구현에서는 actor와 critic을 따로 모델로 만들어서 따로 따로 업데이트를 하지만 하나로 만든다면 loss로 한 번만 업데이트하면 됩니다. 또한 entropy loss를 최종 loss에 더해서 regularization 효과를 볼 수도 있습니다. Critic loss에 clip 해주는 것은 OpenAI baseline의 ppo2 코드를 참조하였습니다.
# step 2: get value loss and actor loss and update actor & critic
for epoch in range(10):
np.random.shuffle(arr)
for i in range(n // hp.batch_size):
batch_index = arr[hp.batch_size * i: hp.batch_size * (i + 1)]
batch_index = torch.LongTensor(batch_index)
inputs = torch.Tensor(states)[batch_index]
returns_samples = returns.unsqueeze(1)[batch_index]
advants_samples = advants.unsqueeze(1)[batch_index]
actions_samples = torch.Tensor(actions)[batch_index]
oldvalue_samples = old_values[batch_index].detach()
loss, ratio = surrogate_loss(actor, advants_samples, inputs,
old_policy.detach(), actions_samples,
batch_index)
values = critic(inputs)
clipped_values = oldvalue_samples + \\\\
torch.clamp(values - oldvalue_samples,
-hp.clip_param,
hp.clip_param)
critic_loss1 = criterion(clipped_values, returns_samples)
critic_loss2 = criterion(values, returns_samples)
critic_loss = torch.max(critic_loss1, critic_loss2).mean()
clipped_ratio = torch.clamp(ratio,
1.0 - hp.clip_param,
1.0 + hp.clip_param)
clipped_loss = clipped_ratio * advants_samples
actor_loss = -torch.min(loss, clipped_loss).mean()
loss = actor_loss + 0.5 * critic_loss
critic_optim.zero_grad()
loss.backward(retain_graph=True)
critic_optim.step()
actor_optim.zero_grad()
loss.backward()
actor_optim.step()PPO의 학습 결과는 다음과 같습니다.

2. Unity ml-agent 학습
Mujoco Hopper(half-cheetah와 같은 것도)에 Vanilla PG, TNPG, TRPO, PPO를 구현해서 적용했습니다. Mujoco의 경우 이미 Hyper parameter와 같은 정보들이 논문이나 블로그에 있기 때문에 상대적으로 continuous control로 시작하기에는 좋습니다. 맨 처음에 말했듯이 Mujoco는 1달만 무료이고 그 이후부터 유료이며 확장성이 떨어집니다. 좀 더 general한 agent를 학습시키기에 좋은 환경이 필요합니다. 따라서 Unity ml-agent를 살펴봤습니다. Repository는 다음과 같습니다.
현재 Unity ml-agent에서 기본으로 제공하는 환경은 다음과 같습니다. Unity ml-agent는 기존 Unity를 그대로 사용하면서 쉽게 강화학습 에이전트를 붙일 수 있도록 설계되어 있습니다. Unity ml-agent에서는 Walker 환경에서 저희가 살펴본 알고리즘 중에 가장 최신 알고리즘은 PPO를 적용해봤습니다. 이 포스트를 보시는 분들은 이 많은 다른 환경에 자유롭게 저희 코드를 적용할 수 있습니다.
Unity ml-agent를 이용해서 강화학습을 하기 위해서는 다음과 같이 진행됩니다. 단계별로 설명하겠습니다.
- Unity에서 환경 만들기
- Python에서 unity 환경 불러와서 테스트하기
- 기존에 하던대로 학습하기
2.1 Walker 환경 만들기
강화학습을 하는 많은 분들이 Unity를 한 번도 다뤄보지 않은 경우가 많습니다. 저도 그런 경우라서 어떻게 환경을 만들어야할지 처음에는 감이 잡히지 않았습니다. 하지만 Unity ml-agent에서는 상당히 자세한 guide를 제공합니다. 다음은 Unity ml-agent의 가장 기본적인 환경인 3DBall에 대한 tutorial입니다. 설치 guide도 제공하고 있으니 참고하시면 될 것 같습니다.
Unity ml-agent에서 제공하는 3DBall tutorial을 참고해서 Walker 환경을 만들었습니다. Walker 환경을 만드는 과정을 간단히 말씀드리겠습니다. 다음 그림의 단계들을 동일하므로 따라하시면 됩니다. Unity를 열고 unity-environment로 들어가시면 됩니다.
<img src="https://www.dropbox.com/s/fbdqg781w46a5mz/Screenshot 2018-08-24 14.50.50.png?dl=1">
그러면 화면 하단에서 다음과 같은 것을 볼 수 있습니다. Assets/ML-Agents/Examples로 들어가보면 Walker가 있습니다. Scenes에서 Walker를 더블클릭하면 됩니다.
<img src="https://www.dropbox.com/s/h349xml3faln0wy/Screenshot 2018-08-24 14.52.14.png?dl=1">
더블클릭해서 나온 화면에서 오른쪽 상단의 파란색 화살표를 누르면 환경이 실행이 됩니다. 저희가 학습하고자 하는 agent는 바로 이녀석입니다. 왼쪽 리스트를 보면 WalkerPair가 11개가 있는 것을 볼 수 있습니다. Unity ml-agent 환경은 기본적으로 Multi-agent로 학습하도록 설정되어있습니다. 따라서 여러개의 Walker들이 화면에 보이는 것입니다.
<img src="https://www.dropbox.com/s/cy8m5kqdmkhopjo/Screenshot 2018-08-24 14.54.57.png?dl=1">
리스트 중에 Walker Academy를 클릭해서 그 하위에 있는 WalkerBrain을 더블클릭합니다. 그러면 화면 오른쪽에 다음과 같은 Brain 설정을 볼 수 있습니다. Brain은 쉽게 말해서 Agent라고 생각하면 됩니다. 이 Agent는 상태로 212차원의 vector가 주어지며 다 continuous한 값을 가집니다. 행동은 39개의 행동을 할 수 있으며 다 Continuous입니다. Mujoco에 비해서 상태나 행동의 차원이 상당히 높습니다. 여기서 중요한 것은 Brain Type입니다. Brain type은 internal, external, player, heuristic이 있습니다. player로 type을 설정하고 화면 상단의 play 버튼을 누르면 여러분이 agent를 움직일 수 있습니다. 하지만 Walker는 사람이 움직이는게 거의 불가능하므로 player 기능은 사용할 수 없습니다. 다른 환경에서는 사용해볼 수 있으니 재미로 한 번 플레이해보시면 좋습니다!

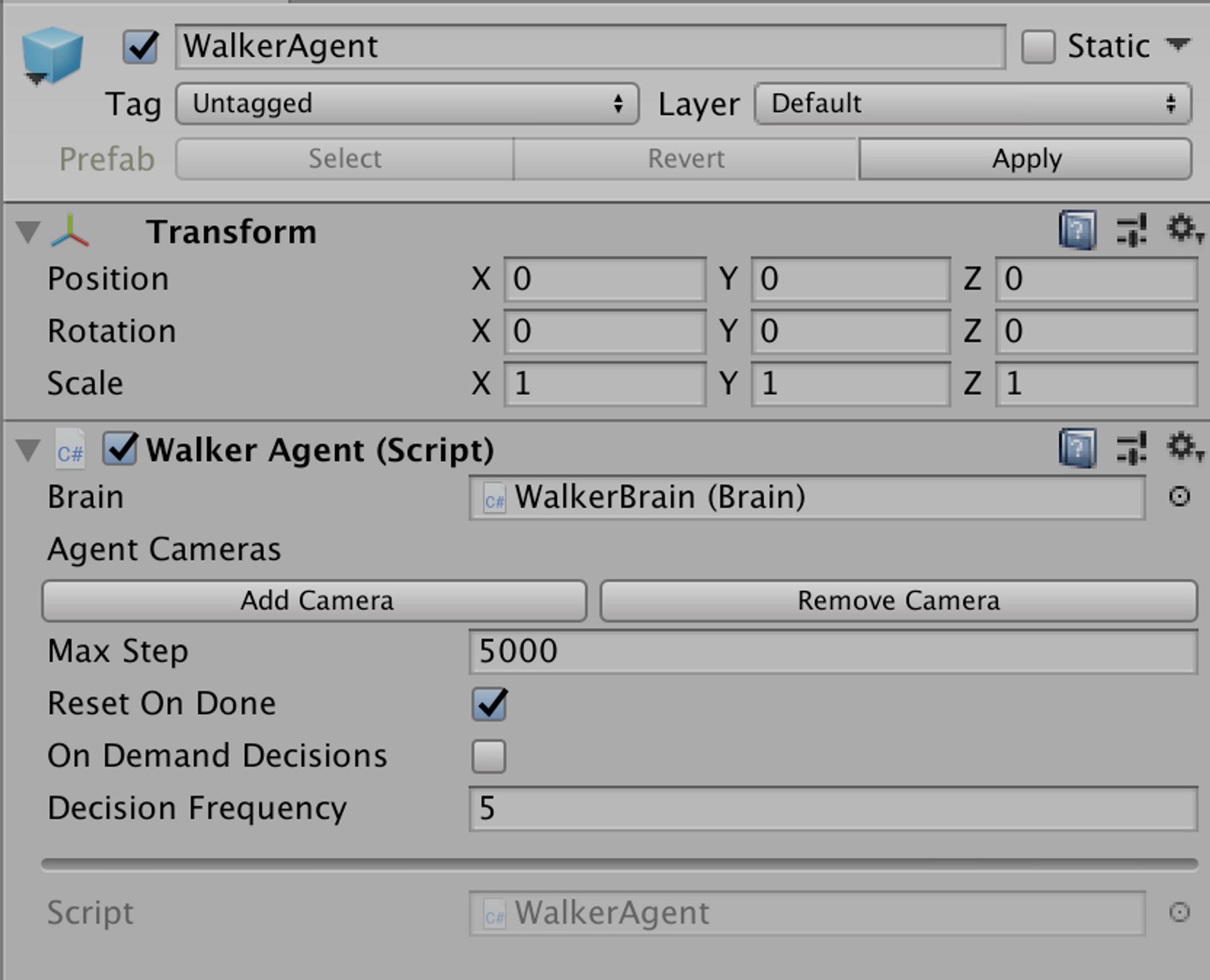
이번에는 WalkerPair에서 WalkerAgent를 더블클릭해보겠습니다. 이 설정을 보아 5000 step이 episode의 max step인 것을 볼 수 있습니다.
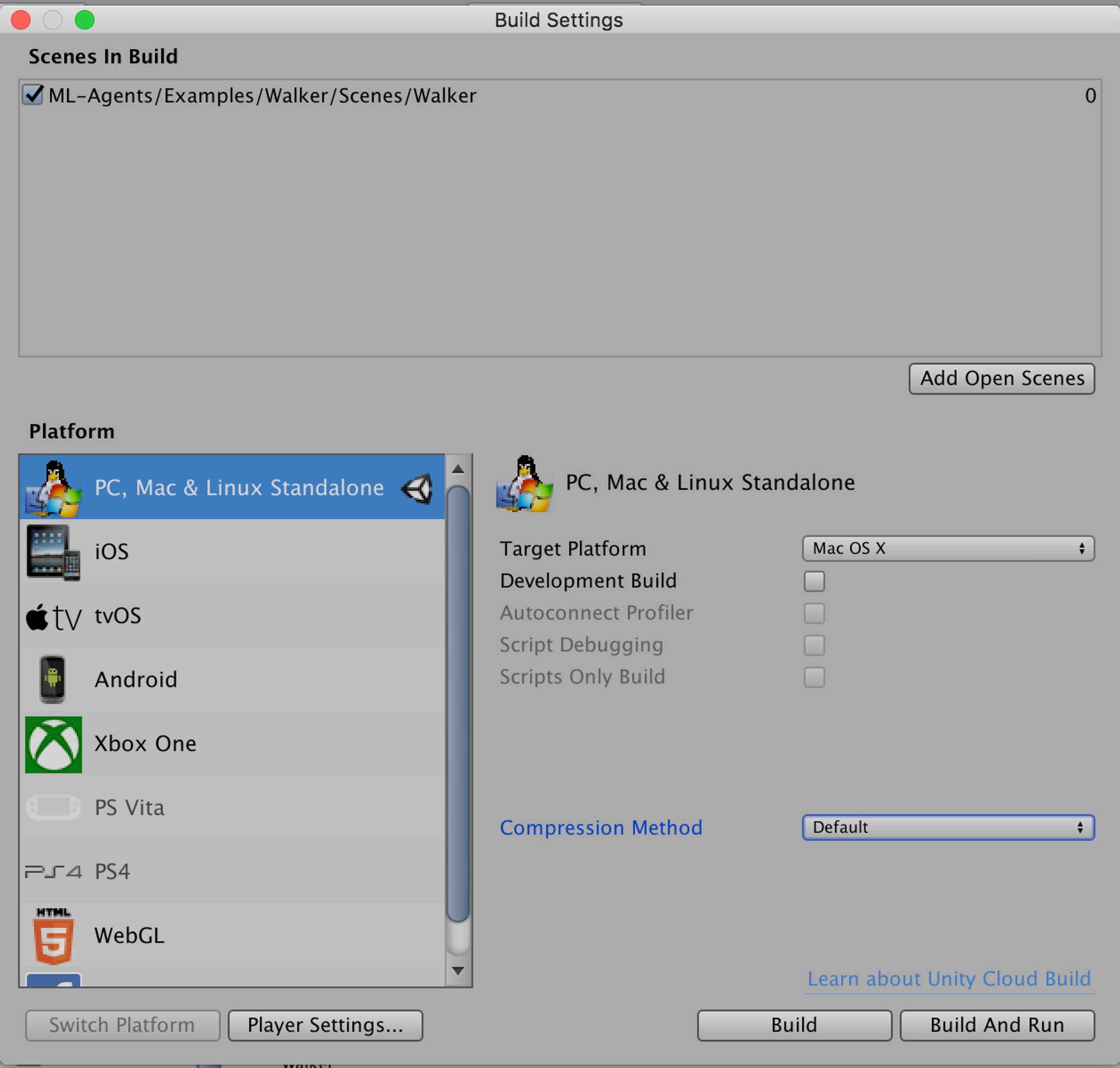
이제 상단 file menu에서 build setting에 들어갑니다. 환경을 build해서 python 코드에서 import하기 위해서입니다. 물론 unity 환경과 python 코드를 binding해주는 부분은 ml-agent 코드 안에 있습니다. Build 버튼을 누르면 환경이 build가 됩니다.
2.2 Python에서 unity 환경 불러와서 테스트하기
환경을 build 했으면 build한 환경을 python에서 불러와서 random action으로 테스트해봅니다. 환경을 테스트하는 코드는 pg_travel repository에서 unity 폴더 밑에 있습니다. test_env.py라는 코드는 간단하게 다음과 같습니다. Build한 walker 환경은 env라는 폴더 밑에 넣어줍니다. unityagent를 import하는데 ml-agent를 git clone 해서 python 폴더 내에서 "python setup.py install"을 실행했다면 문제없이 import 됩니다. UnityEnvironment를 통해 env라는 환경을 선언할 수 있습니다. 이렇게 선언하고 나면 gym과 상당히 유사한 형태로 환경과 상호작용이 가능합니다.
import numpy as np
from unityagents import UnityEnvironment
from utils.utils import get_action
if __name__=="__main__":
env_name = "./env/walker_test"
train_mode = False
env = UnityEnvironment(file_name=env_name)
default_brain = env.brain_names[0]
brain = env.brains[default_brain]
env_info = env.reset(train_mode=train_mode)[default_brain]
num_inputs = brain.vector_observation_space_size
num_actions = brain.vector_action_space_size
num_agent = env._n_agents[default_brain]
print('the size of input dimension is ', num_inputs)
print('the size of action dimension is ', num_actions)
print('the number of agents is ', num_agent)
score = 0
episode = 0
actions = [0 for i in range(num_actions)] * num_agent
for iter in range(1000):
env_info = env.step(actions)[default_brain]
rewards = env_info.rewards
dones = env_info.local_done
score += rewards[0]
if dones[0]:
episode += 1
score = 0
print('{}th episode : mean score of 1st agent is {:.2f}'.format(
episode, score))위 코드를 실행하면 다음과 같이 실행창에 뜹니다. External brain인 것을 알 수 있고 default_brain은 brain 중에 하나만 가져왔기 때문에 number of brain은 1이라고 출력합니다. input dimension은 212이고 action dimension은 39이고 agent 수는 11인 것으로봐서 제대로 환경이 불러와진 것을 확인할 수 있습니다.

이 환경에서 행동하려면 agent 숫자만큼 행동을 줘야합니다. 모두 0로 행동을 주고 실행하면 다음과 같이 뒤로 넘어지는 행동을 반복합니다. env.step(actions)[default_brain]으로 env_info를 받아오면 거기서부터 reward와 done, next_state를 받아올 수 있습니다. 이제 학습하기만 하면 됩니다.
2.3 Walker 학습하기
기존에 Mujoco에 적용했던 PPO 코드를 그대로 Walker에 적용하니 잘 학습이 안되었습니다. 다음 사진이 저희가 중간 해커톤으로 모여서 이 상황을 공유할 때의 사진입니다.

Unity ml-agent에서는 PPO를 기본 agent로 제공합니다. 학습 코드도 제공하기 때문에 mujoco에 적용했던 코드와의 차이점을 분석할 수 있었습니다. mujoco 코드와 ml-agent baseline 코드의 차이점은 다음과 같습니다.
- agent 여러개를 이용, 별개의 memory에 저장한 후에 gradient를 합침
- GAE 및 time horizon 등 hyper parameter가 다름
- Actor와 Critic의 layer가 1층 더 두꺼우며 hidden layer 자체의 사이즈도 더 큼
- hidden layer의 activation function이 tanh가 아닌 swish
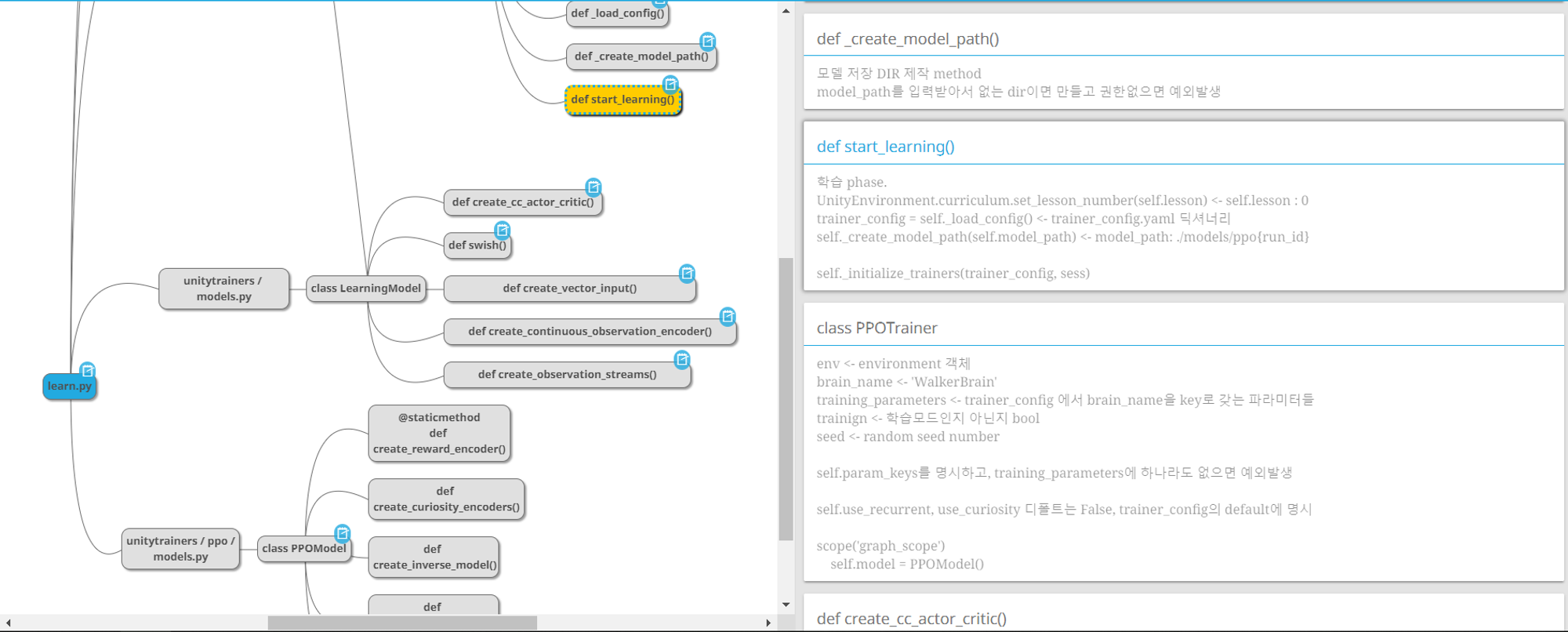
ml-agent baseline 코드리뷰할 때 작성했던 마인드맵은 다음과 같습니다.
크게는 두 가지를 개선해서 성능이 많이 향상했습니다.
- Network 수정
- multi-agent를 활용해서 학습
Network 코드는 다음과 같습니다. Hidden Layer를 하나 더 늘렸으며 swish activation function을 사용할 수 있도록 변경했습니다. 사실 swish라는 activation function은 처음 들어보는 생소한 함수였습니다. 하지만 ml-agent baseline에서 사용했다는 사실과 구현이 상당히 간단하다는 점에서 저희 코드에 적용했습니다. 단순히 x * sigmoid(x) 를 하면 됩니다. swish는 별거 아닌 것 같지만 상당한 성능 개선을 가져다줬습니다. 사실 ReLU나 ELU 등 여러 다른 activation function을 적용해서 비교해보는게 best긴 하지만 시간 관계상 그렇게까지 테스트해보지는 못했습니다. 기존에 TRPO나 PPO는 왜 tanh를 사용했었는지도 의문인 점입니다.
class Actor(nn.Module):
def __init__(self, num_inputs, num_outputs, args):
self.args = args
self.num_inputs = num_inputs
self.num_outputs = num_outputs
super(Actor, self).__init__()
self.fc1 = nn.Linear(num_inputs, args.hidden_size)
self.fc2 = nn.Linear(args.hidden_size, args.hidden_size)
self.fc3 = nn.Linear(args.hidden_size, args.hidden_size)
self.fc4 = nn.Linear(args.hidden_size, num_outputs)
self.fc4.weight.data.mul_(0.1)
self.fc4.bias.data.mul_(0.0)
def forward(self, x):
if self.args.activation == 'tanh':
x = F.tanh(self.fc1(x))
x = F.tanh(self.fc2(x))
x = F.tanh(self.fc3(x))
mu = self.fc4(x)
elif self.args.activation == 'swish':
x = self.fc1(x)
x = x * F.sigmoid(x)
x = self.fc2(x)
x = x * F.sigmoid(x)
x = self.fc3(x)
x = x * F.sigmoid(x)
mu = self.fc4(x)
else:
raise ValueError
logstd = torch.zeros_like(mu)
std = torch.exp(logstd)
return mu, std, logstdswish와 tanh를 사용한 학습을 비교한 그래프입니다. 하늘색 그래프가 swish를 사용한 결과, 파란색이 tanh를 사용한 결과입니다. score는 episode 마다의 reward의 합입니다.
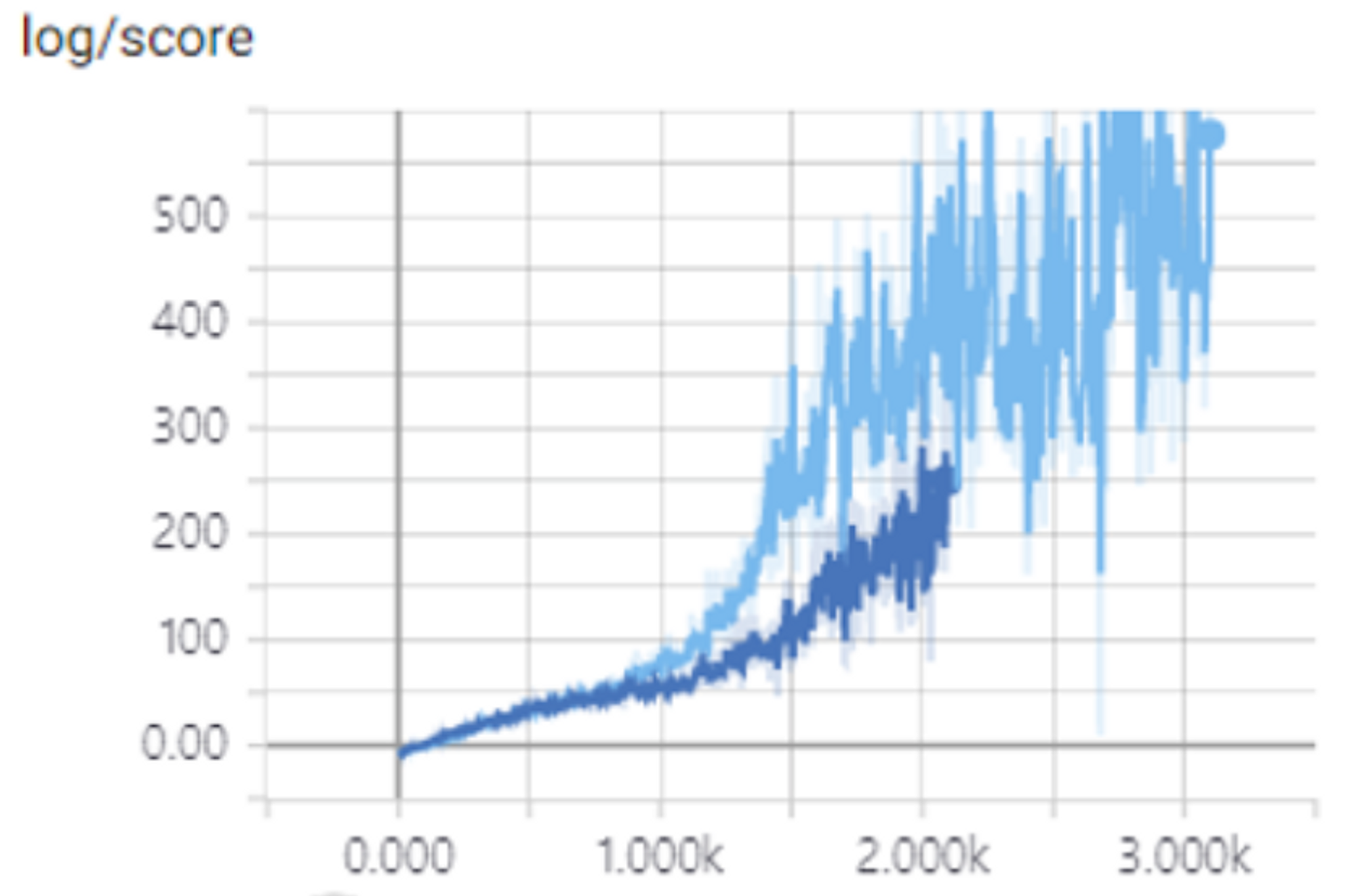
이제 multi-agent로 학습하도록 변경하면 됩니다. PPO의 경우 memory에 time horizon 동안의 sample을 시간순서대로 저장하고 GAE를 구한 이후에 minibatch로 추출해서 학습합니다. 따라서 여러개의 agent로 학습하기 위해서는 memory를 따로 만들어서 각각의 GAE를 구해서 학습해야합니다. Unity에서는 Mujoco에서 했던 것처럼 deque로 memory를 만들지 않고 따로 named tuple로 구현한 memory class를 import 해서 사용했습니다. utils 폴더 밑에 memory.py 코드에 구현되어있으며 코드는 https://github.com/pytorch/tutorials/blob/master/Reinforcement (Q-)Learning with PyTorch.ipynb 에서 가져왔습니다.
state, action, reward, mask를 저장하는데 불러올 때 각각을 따로 불러올 수 있기 때문에 비효율적 시간을 많이 줄여줍니다.
Transition = namedtuple('Transition', ('state', 'action', 'reward', 'mask'))
class Memory(object):
def __init__(self):
self.memory = []
def push(self, state, action, reward, mask):
"""Saves a transition."""
self.memory.append(Transition(state, action, reward, mask))
def sample(self):
return Transition(*zip(*self.memory))
def __len__(self):
return len(self.memory)main.py 에서는 이 memory를 agent의 개수만큼 생성합니다.
memory = [Memory() for _ in range(num_agent)]sample을 저장할 때도 agent마다 따로 따로 저장합니다.
for i in range(num_agent):
memory[i].push(states[i], actions[i], rewards[i], masks[i])time horizon이 끝나면 모은 sample 들을 가지고 학습하기 위한 값으로 만드는 과정을 진행합니다. 각각의 memory를 가지고 GAE와 old_policy, old_value 등을 계산해서 하나의 batch로 합칩니다. 그렇게 train_model 메소드에 전달하면 기존과 동일하게 agent를 업데이트합니다.
sts, ats, returns, advants, old_policy, old_value = [], [], [], [], [], []
for i in range(num_agent):
batch = memory[i].sample()
st, at, rt, adv, old_p, old_v = process_memory(actor, critic, batch, args)
sts.append(st)
ats.append(at)
returns.append(rt)
advants.append(adv)
old_policy.append(old_p)
old_value.append(old_v)
sts = torch.cat(sts)
ats = torch.cat(ats)
returns = torch.cat(returns)
advants = torch.cat(advants)
old_policy = torch.cat(old_policy)
old_value = torch.cat(old_value)
train_model(actor, critic, actor_optim, critic_optim, sts, ats, returns, advants,
old_policy, old_value, args)이렇게 학습한 에이전트는 다음과 같이 걷습니다. 이렇게 walker를 학습시키고 나니 어떻게 하면 사람처럼 자연스럽게 걷는 것을 agent 스스로 학습할 수 있을까라는 고민을 하게 되었습니다.
<center><img src="https://www.dropbox.com/s/fyz1kn5v92l3rrk/plane-595.gif?dl=1"></center>
{kind=link}
Unity ml-agent에서 제공하는 pretrained된 모델을 다음과 같이 걷습니다. 저희가 학습한 agent와 상당히 다르게 걷는데 왜 그런 차이가 나는지도 분석하고 싶습니다.
<center><img src="https://www.dropbox.com/s/xwz766g7c4eiaia/plane-unity.gif?dl=1"></center>
{kind=link}
3. Unity Curved Surface 제작 및 학습기
Unity ml-agent에서 제공하는 기본 Walker 환경에서 학습하고 나니 바닥을 조금 울퉁불퉁하게 혹은 경사가 진 곳에서 걷는 것을 학습해보고 싶다라는 생각이 들었습니다. 따라서 간단하게 걷는 배경을 다르게 하는 시도를 해봤습니다.
3.1 Curved Surface 만들기
Agent가 걸어갈 배경을 처음부터 만드는 것보다 구할 수 있다면 만들어진 배경을 구하기로 했습니다. Unity를 무료라는 점에서 선택했듯이 배경을 무료로 구할 수 있는 방법을 선택했습니다.
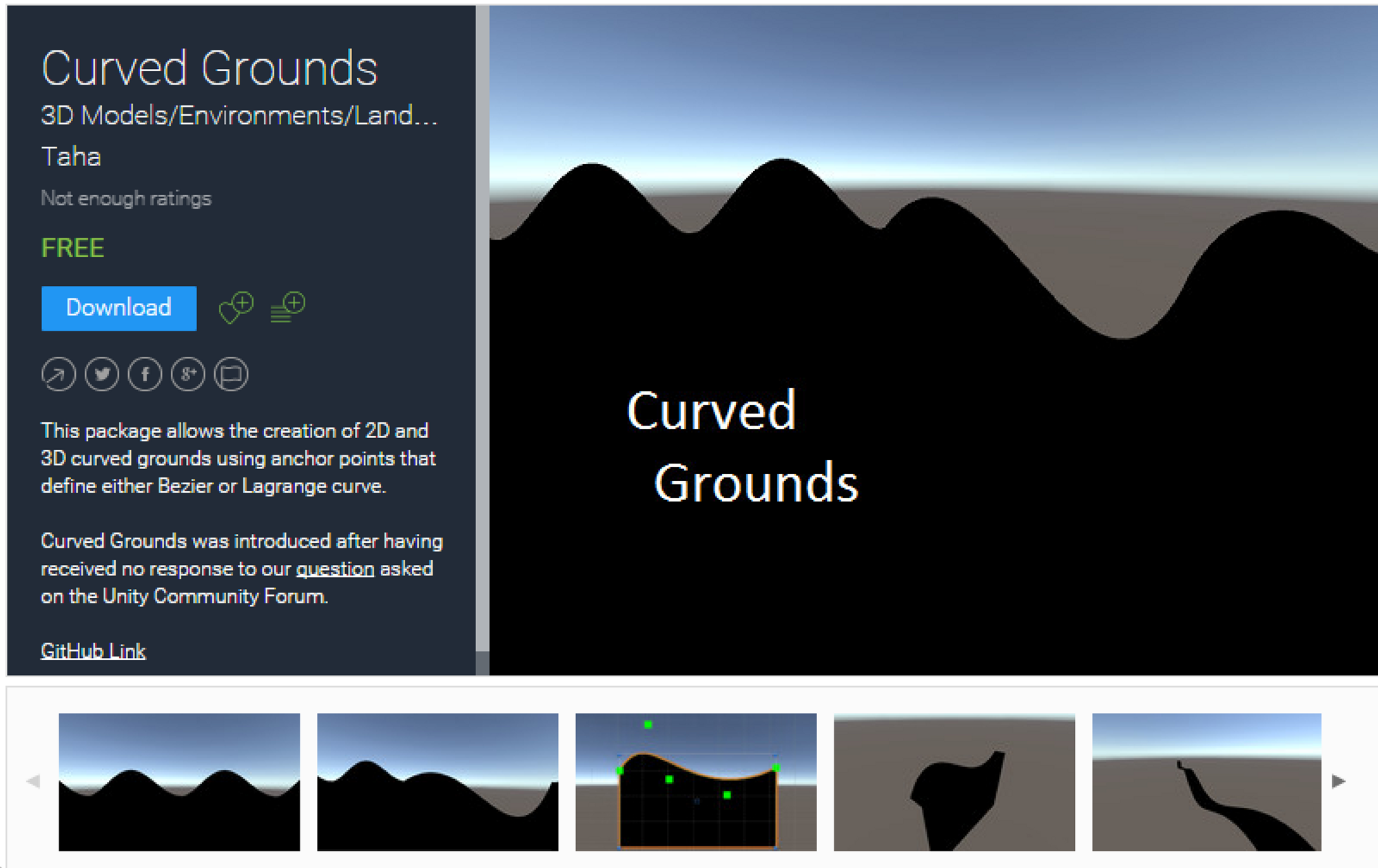
무료로 공개되어있는 Unity 배경 중에서 Curved Ground 라는 것을 가져와서 작업하기로 했습니다. 이 환경 같은 경우 spline을 그리듯이 중간의 점을 이동시키면서 사용자가 곡면을 수정할 수 있습니다.
간단하게 곡면을 만들어서 공을 굴려보면 다음과 같이 잘 굴러갑니다.
여러 에이전트가 학습할 수 있도록 오목한 경사면을 제작했습니다. 초반의 모습은 다음과 같았습니다.

하지만 최종으로는 다음과 같은 곡면으로 사용했습니다. 위 사진의 배경과 아래 사진의 배경이 다른 점은 slope 길이, 내리막 경사, 오르막 경사입니다. Slope 길이의 경우 길이를 기존 plane 과 동일하게 했더니, 오르막 올라가는 부분이 학습이 잘 안 되었습니다. 따라서 길이를 줄였습니다. 내리막 경사의 경우 너무 경사지면 학습이 잘 안 되고, 너무 완만하니 내리막 티가 잘 안 나기 때문에 적절한 경사를 설정했습니다. 오르막 경사의 경우 내리막보다는 오르막이 더 어려울 것이라고 판단해서 오르막 경사를 낮게 설정했습니다.

3.2 Curved Surface에서 학습하기
위 환경으로 학습을 할 때, agent가 너무 초반에 빨리 쓰러지는 현상이 발생했습니다. 혹시 발의 각도가 문제일까 싶어서 발 각도를 변경해보았습니다.

하지만 역시 평지에서 걷는 것처럼 걷도록 학습이 안되었습니다. 이 환경에서 더 잘 학습하려면 더 여러가지를 시도해봐야할 것 같습니다. (그래도 걷는 게 기특합니다..)


4. 구현 후기
피지여행 구현팀은 총 4명으로 진행했습니다. 각 팀원의 후기를 적어보겠습니다.
- 팀원 장수영: 사랑합니다. 행복합니다.
- 팀원 공민서: 제가 핵심적인 기능을 구현하지는 못했지만 무조코 설치와 모델 테스트를 맡으면서 딥마인드나 openai의 영상으로만 보던 에이전트의 성장과정을 눈으로 지켜볼 수 있었습니다. 제대로 서있지도 못하던 hopper가 어느정도 훈련이 되고서는 넘어지려하다가도 추진력을 얻기위해 웅크렸다 뛰는 것을 관찰하는 것도 재미있고 육아일기를 보는 아버지의 마음을 조금이나마 이해할 수 있었습니다. 텐서보드를 넣는 걸 깜빡해 일일히 에피소드 별 스코어를 시각화 하면서 텐서보드의 소중함을 알았습니다. 유니티 코드리뷰를 하면서도 시스템 아키텍쳐 설계에 대해서도 배울 점이 있었던 것 같고 swish라는 활성화함수의 존재도 알았었고 curiosity도 알게되었고 역시 다른 사람의 코드를 읽는 것도 많은 공부가 된다고 되새기던 시간이었습니다. 물론 너무 크기가 방대해서 가독성은 많이 떨어졌습니다만 무조코보다 유니티가 훨씬 흥할거라고 생각했습니다. 마지막으로 누구 하나 열정적이지 않은 사람이 없이 치열한 고민을 함께 한 PG여행팀 분들, 저의 부족함과 상생의 기쁨을 알게해주셔서 정말 감사드립니다.
- 팀원 양혁렬: 여러 에이전트가 함께하면 더 잘하는 걸 보면서 새삼 좋은 분들과 함께 할 수 있어서 행복했습니다
- 팀원 이웅원: 저희가 직접 바닥부터 다 구현했던 것은 아니지만 구현을 해보면서 논문의 내용을 더 잘 이해할 수 있었습니다. 논문에 나와있지 않은 여러 노하우가 필요한 점들도 많았습니다. 역시 코드로 보고 성능 재현이 되어야 제대로 알고리즘을 이해하게 된다는 것을 다시 느낀 시간이었습니다. 또한 강화학습은 역시 환경세팅이 어렵다는 생각을 했습니다. 하지만 unity ml-agent를 사용해보면서 앞으로 강화학습 환경으로서 가능성이 상당히 크다는 생각을 했습니다. 또한 구현팀과 슬랙, 깃헙으로 협업하면서 온라인 협업에 대해서 더 배워가는 것 같습니다. 아직은 익숙하지 않지만 앞으로는 마치 바로 옆에서 같이 코딩하는 것 같이 될 거라고 생각합니다.
'프로젝트 > 피지여행' 카테고리의 다른 글
| 8. Proximal Policy Optimization (0) | 2023.03.12 |
|---|---|
| 7. High-Dimensional Continuous Control using Generalized Advantage Estimation (0) | 2023.03.12 |
| 6. Trust Region Policy Optimization (0) | 2023.03.08 |
| 5. Natural Policy Gradient (0) | 2023.03.06 |
| 4. Deep Deterministic Policy Gradient (DDPG) (0) | 2023.03.06 |